动态规划
单例模式
ssm
数据标注
青少年编程
文字
MIT
DDIM
kubernetes
C++语法,动态绑定
vue3生命周期
CyclicBarrier
信息系统项目管理师
BFC
android 各 版本
Conditional注解
次世代建模
mulesoft
数据结构和算法
证件照
实时计算
2024/4/12 15:11:05
【大数据】Flink SQL 语法篇(二):WITH、SELECT WHERE、SELECT DISTINCT
Flink SQL 语法篇(二) 1.WITH 子句2.SELECT & WHERE 子句3.SELECT DISTINCT 子句 1.WITH 子句
应用场景(支持 Batch / Streaming):With 语句和离线 Hive SQL With 语句一样的,语法糖 1,使用…

【大数据】Flink 架构(四):状态管理
Flink 架构(四):状态管理 1.算子状态2.键值分区状态3.状态后端4.有状态算子的扩缩容4.1 带有键值分区状态的算子4.2 带有算子列表状态的算子4.3 带有算子联合列表状态的算子4.4 带有算子广播状态的算子 在前面的博客中我们指出,大…
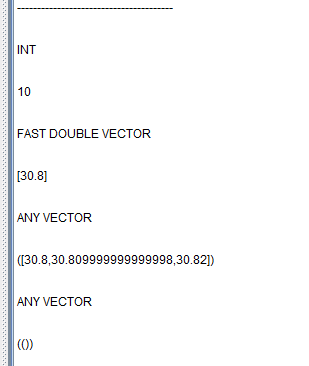
量化因子在 DolphinDB 中的流式实现攻略
DolphinDB 是一款高性能分布式时序数据库。与传统的关系数据库和常见的时序数据库不同,DolphinDB 不仅提供了高速存取时序数据的基本功能,而且内置了向量化的多范式编程语言与强大的计算引擎。DolphinDB 的计算引擎不仅可以用于量化金融的回测和研发&…

【大数据】Flink SQL 语法篇(一):CREATE
Flink SQL 语法篇(一) 1.建表语句2.表中的列2.1 常规列(物理列)2.2 元数据列2.3 计算列 3.定义 Watermark4.Create Table With 子句5.Create Table Like 子句 CREATE 语句用于向当前或指定的 Catalog 中注册库、表、视图或函数。注…

Flink之状态管理
Flink状态管理 状态概述状态分类 键控、按键分区状态概述值状态 ValueState列表状态 ListStateMap状态 MapState归约状态 ReducingState聚合状态 Aggregating State 算子状态概述列表状态 ListState联合列表状态 UnionListState广播状态 Broadcast State 状态有效期 (TTL)概述S…

Spark学习笔记(四):SparkStreaming实现实时计算
SparkStreaming是Spark的一个流式计算框架,它支持对许多数据源进行实时监听,例如Kafka, Flume, Kinesis, or TCP sockets,并实现实时计算的能力,但准确来说应该是伪实时,因为它的基本原理就是定时接收数据流࿰…
【大数据】Flink 中的状态管理
Flink 中的状态管理 1.算子状态2.键值分区状态3.状态后端4.有状态算子的扩缩容4.1 带有键值分区状态的算子4.2 带有算子列表状态的算子4.3 带有算子联合列表状态的算子4.4 带有算子广播状态的算子 在前面的博客中我们指出,大部分的流式应用都是有状态的。很多算子都…
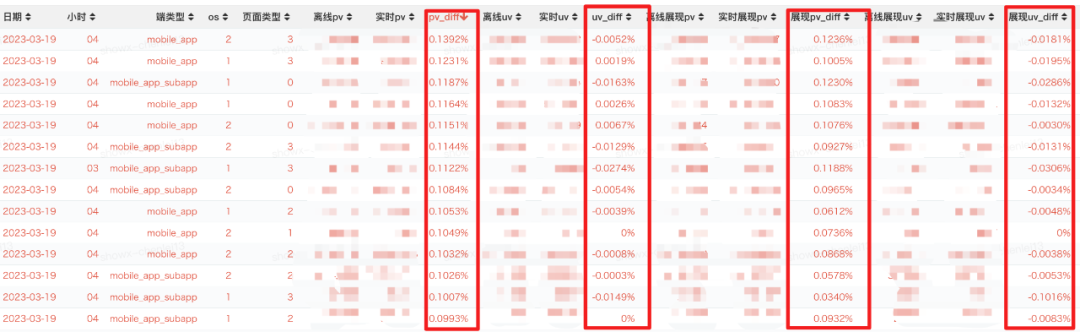
精准水位在流批一体数据仓库的探索和实践
作者 | 浮生若梦的石头 导读 随着实时计算技术在大数据中的广泛应用,数据的时效性得到大幅度,但是实际应用场景中,除了时效性,还面临着更高的技术要求。 本文结合实时计算的水位技术在流批一体数据仓库中的探索和实践,…

Spark学习笔记(三):SparkStreaming实现对文件夹和socket的监听
SparkStreaming是Spark的一个流式计算框架,它支持对许多数据源进行实时监听,例如Kafka, Flume, Kinesis, TCP sockets,甚至文件夹,并实现实时计算的能力。
对文件夹的监听
def fileStreaming(): Unit {/*** 监听文件夹的新增文件…

【大数据】Flink 详解(九):SQL 篇 Ⅱ
《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章:
【大数据】Flink 详解(一):基础篇【大数据】Flink 详解(二):核心篇 Ⅰ【大数据】Flink 详解&…

【大数据】流处理基础概念(一):Dataflow 编程基础、并行流处理
流处理基础概念(一):Dataflow 编程基础、并行流处理 1.Dataflow 编程基础1.1 Dataflow 图1.2 数据并行和任务并行1.3 数据交换策略 2.并行流处理2.1 延迟与吞吐2.1.1 延迟2.1.2 吞吐2.1.3 延迟与吞吐 2.2 数据流上的操作2.2.1 数据接入和数据…
【大数据】流处理基础概念(三):状态和一致性模型(任务故障、结果保障)
流处理基础概念(一):Dataflow 编程基础、并行流处理流处理基础概念(二):时间语义(处理时间、事件时间、水位线)流处理基础概念(三):状态和一致性模…

【大数据】深入浅出 Apache Flink:架构、案例和优势
深入浅出 Apache Flink:架构、案例和优势 1.现代大数据架构1.1 什么是批处理?1.2 什么是流处理? 2.Apache Flink 项目2.1 处理无界和有界数据流2.2 有界数据流2.3 无界流 3.Apache Flink 架构和关键组件3.1 Flink 架构3.2 Flink 生态3.2.1 Da…

【大数据】详解 Flink 中的 WaterMark
详解 Flink 中的 WaterMark 1.基础概念1.1 流处理1.2 乱序1.3 窗口及其生命周期1.4 Keyed vs Non-Keyed1.5 Flink 中的时间 2.Watermark2.1 案例一2.2 案例二2.3 如何设置最大乱序时间2.4 延迟数据重定向 3.在 DDL 中的定义3.1 事件时间3.2 处理时间 1.基础概念
1.1 流处理
流…